NanoPi NEO3のSoCの冷却力を高めたのでこれで全力で動いても大丈夫になった筈。
これまで2回計測したUnixBenchではガッカリな結果だったが・・・
========================================================================
BYTE UNIX Benchmarks (Version 5.1.3)
System: nanopineo3: GNU/Linux
OS: GNU/Linux -- 5.7.10-rockchip64 -- #trunk SMP PREEMPT Mon Jul 27 22:40:16 JST 2020
Machine: aarch64 (unknown)
Language: en_US.utf8 (charmap="UTF-8", collate="UTF-8")
11:00:01 up 2 days, 23:00, 1 user, load average: 0.22, 0.53, 0.37; runlevel 5
------------------------------------------------------------------------
Benchmark Run: 金 8月 14 2020 11:00:01 - 11:28:46
0 CPUs in system; running 1 parallel copy of tests
Dhrystone 2 using register variables 7656264.5 lps (10.0 s, 7 samples)
Double-Precision Whetstone 1765.9 MWIPS (9.8 s, 7 samples)
Execl Throughput 870.2 lps (30.0 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 140216.0 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 39513.3 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 392950.9 KBps (30.0 s, 2 samples)
Pipe Throughput 285418.7 lps (10.0 s, 7 samples)
Pipe-based Context Switching 50954.1 lps (10.0 s, 7 samples)
Process Creation 1769.8 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 2341.6 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 608.9 lpm (60.0 s, 2 samples)
System Call Overhead 466137.3 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 7656264.5 656.1
Double-Precision Whetstone 55.0 1765.9 321.1
Execl Throughput 43.0 870.2 202.4
File Copy 1024 bufsize 2000 maxblocks 3960.0 140216.0 354.1
File Copy 256 bufsize 500 maxblocks 1655.0 39513.3 238.8
File Copy 4096 bufsize 8000 maxblocks 5800.0 392950.9 677.5
Pipe Throughput 12440.0 285418.7 229.4
Pipe-based Context Switching 4000.0 50954.1 127.4
Process Creation 126.0 1769.8 140.5
Shell Scripts (1 concurrent) 42.4 2341.6 552.3
Shell Scripts (8 concurrent) 6.0 608.9 1014.9
System Call Overhead 15000.0 466137.3 310.8
========
System Benchmarks Index Score 331.3
------------------------------------------------------------------------
Benchmark Run: 金 8月 14 2020 11:28:46 - 11:57:58
0 CPUs in system; running 4 parallel copies of tests
Dhrystone 2 using register variables 30564936.4 lps (10.0 s, 7 samples)
Double-Precision Whetstone 7065.3 MWIPS (9.8 s, 7 samples)
Execl Throughput 2497.8 lps (29.9 s, 2 samples)
File Copy 1024 bufsize 2000 maxblocks 242698.9 KBps (30.0 s, 2 samples)
File Copy 256 bufsize 500 maxblocks 65123.7 KBps (30.0 s, 2 samples)
File Copy 4096 bufsize 8000 maxblocks 730181.3 KBps (30.0 s, 2 samples)
Pipe Throughput 1133962.0 lps (10.0 s, 7 samples)
Pipe-based Context Switching 165331.0 lps (10.0 s, 7 samples)
Process Creation 4611.3 lps (30.0 s, 2 samples)
Shell Scripts (1 concurrent) 4812.3 lpm (60.0 s, 2 samples)
Shell Scripts (8 concurrent) 629.3 lpm (60.2 s, 2 samples)
System Call Overhead 1818031.4 lps (10.0 s, 7 samples)
System Benchmarks Index Values BASELINE RESULT INDEX
Dhrystone 2 using register variables 116700.0 30564936.4 2619.1
Double-Precision Whetstone 55.0 7065.3 1284.6
Execl Throughput 43.0 2497.8 580.9
File Copy 1024 bufsize 2000 maxblocks 3960.0 242698.9 612.9
File Copy 256 bufsize 500 maxblocks 1655.0 65123.7 393.5
File Copy 4096 bufsize 8000 maxblocks 5800.0 730181.3 1258.9
Pipe Throughput 12440.0 1133962.0 911.5
Pipe-based Context Switching 4000.0 165331.0 413.3
Process Creation 126.0 4611.3 366.0
Shell Scripts (1 concurrent) 42.4 4812.3 1135.0
Shell Scripts (8 concurrent) 6.0 629.3 1048.9
System Call Overhead 15000.0 1818031.4 1212.0
========
System Benchmarks Index Score 836.9
UnixBenchを走らせる前にCPUのクロックは1.5GHz固定にした。(終了後もそのまま1.5GHz)
インデックスのスコア(黄字)を見ると、シングルで前回の1.1倍、4パラレルで1.4倍。前回は特に4パラレルで異常にスコアが悪かったのでこれで正常感が強い。前回はNanoPi NEO3標準ヒートシンクで放熱ができてなくて、おそらくリミッターがかかる直前ぎりぎりの温度でUnixBenchを走らせ始めてて、そこから僅かに温度が上がったところでクロックが落とされていたということかしら。
CPUクロック変更
/etc/default/cpufrequtils (変更部分)1 2 | MAX_SPEED=1512000
GOVERNOR=performance
|
$ sudo systemctl restart cpufrequtils
cpufrequtilsサービスを再起動すると1.5GHz固定になる。(システム起動時などは一時的に他のクロックが使われることがある)
CPU温度推移
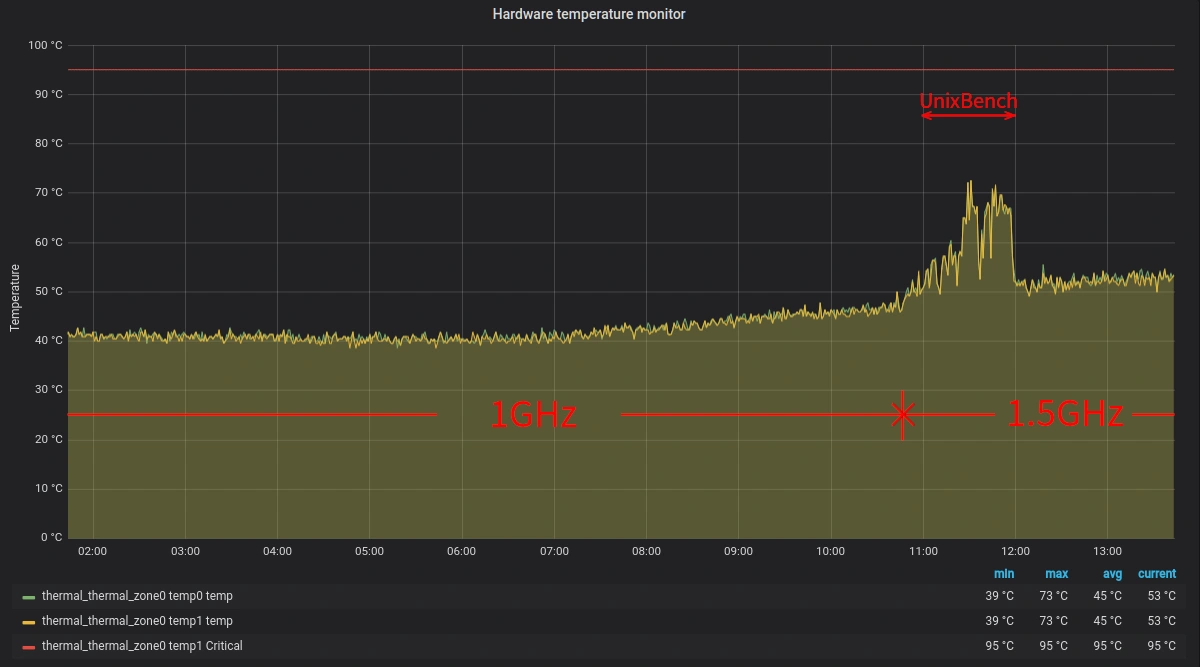
10:50にCPUクロックを1GHzから1.5GHzに変更。11:00から12:00までUnixBenchが動いている。毎日8:00から16:00にかけて温度の上昇局面なのでそれを考慮するとクロック変更後は5℃ほど温度が上昇している感じ。UnixBench中は急上昇しているがそれでも突出したときで70℃程度なので冷却力を高める前の1.5GHzのアイドル時より良好。冷却が効いているなら負荷が高いとき以外は意外と温度は大きく上がらないといえる。NanoPi NEO3標準のちっちゃいヒートシンク使用時は冷却力がきびしくて負荷が小さくて(アイドルで)もクロックの違いで温度が大きく変わるみたい。
自分のNeo3もUnixBenchが振るわなかったんですが(OSはFriendlyWrt クロックはデフォルト。頑張って冷却してUnixBench実行時Max57℃)
ベンチ時グラフを見ていたらShell Scriptsテスト時だけ、システム負荷が特別に大きくなり(他のテストでは上がらない)、あれ?と思い、
試しにマウントしたUSBメモリ(そこそこ速い)にUnixBenchを入れて実行したところ、シングル 302.7 4パラレル 837.2 という結果に。
実行する場所によって変わるみたいです。特にFile Copy のテストが足を引っぱっている。
ご参考までに。
UnixBenchのインデックススコアはCPUの処理以外の結果も含まれるのでストレージの読み書き速度が速くなればその項目が反映されてスコアは向上します。
ただ、今回はCPUの冷却によるスコアの違いを見たかったので冷却変更前と変更後ではおなじmicroSDカードを使っています。
シングルボードコンピュータ(特にmicroSDを使う場合で)は多くの場合はストレージの読み書きが多くない用途で使うと思うのでストレージの読み書き性能はあまり気にしていません。「がとらぼ」では他のUnixBenchの計測でも速さを競おうとは思っていないので速いmicroSDカードは使っていません。余り物のClass2とか4とかクソ遅いのを平気で使ってます。